How the Web works.

If you're starting out in web development or are a bit rusty about the general scaffolding and technologies required to make the web possible, this high level overview could help you avoid time-consuming setbacks. Knowing how the web works enables developers to make informed architectural decisions, pinpoint bottlenecks and errors, and build solutions that are optimised for the medium they're intended for. My intention is to provide enough clarity on the topic without delivering overwhelming details. So let’s begin. Firstly, we’ll set out to define some core concepts, then run through some key processes and technologies. Finally, we’ll wrap up with how these technologies and processes are used to execute the loading of a web page.
Networks
Devices can be connected through a wireless medium such as Wi-Fi or a physical medium such as ethernet cable. Two or more connected devices are considered a Network. When connected these devices can communicate with one another. Wirelessly and physically connected devices can be a part of the same network. This is the founding principle of the Internet. The Internet is a network, a global one.
The Internet
This global network connects millions of computers, each able to communicate with one another. This connection allows us to email, share files, transfer data, play games, stream films and access the World Wide Web. An Internet service provider (ISP) is an organisation that provides services for accessing and using the Internet.
The World Wide Web
Although commonly used interchangeably The World Wide Web, or simply the Web, isn’t the same as the Internet. To help articulate this difference, think of the internet as the roads that connect towns and cities together. The world wide web contains the things you see on the roads like houses and shops. The vehicles are the data moving around - some go between websites and others will be transferring your emails or files across the internet, separately from the web. Another way to look at this difference is; the Internet is infrastructure while the Web is the service on top of that infrastructure. As such, the Internet makes the Web possible but the two are not the same.
There are some underlying differences in the technologies and processes used between services such as email, streaming and browsing the Web. However this is beyond the scope of this article where we’re focusing on the Web.
Clients and Servers
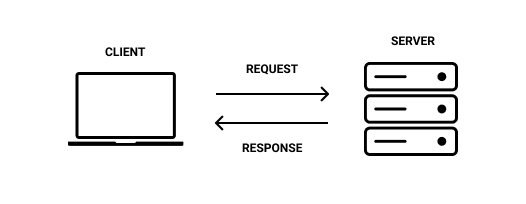
When using the Web we rely on a client-server relationship. Clients, such as web browsers, request and receive information from servers. Servers, on the other hand, receive requests and deliver responses to clients. Requests and responses are dispatched in the form of HTTP messages.
A client, in this instance a laptop, and a server demonstrating the request/response communication relationship.
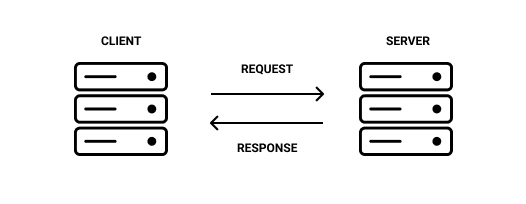
A client is not always the device the user interacts with. A server can also be a client as shown here.
HTTP/HTTPS
Hypertext Transfer Protocol is the protocol used between clients and servers to communicate. Assets such as images, text, documents, video and audio can all be transferred through HTTP messages.
Remember our response and request messages? These are the two types of HTTP messages. Both are composed of the following components: a start-line, some headers, an empty line and finally an optional body component. See MDN for the specifics of an HTTP request.
The S in HTTPS indicates a greater level of security and requires an SSL certificate to use. These certificates ensure transferred data is encrypted making it harder for intermediary parties to read the contents of the messages passed between servers and clients. In other words, this layer of security helps to ensure data (including confidential or sensitive information) remains undisclosed for everyone but its intended recipient.
SSL in action. Note the padlock icon to the left of the URL. This indicates the use of HTTPS and so we can have greater confidence that our security is protected.
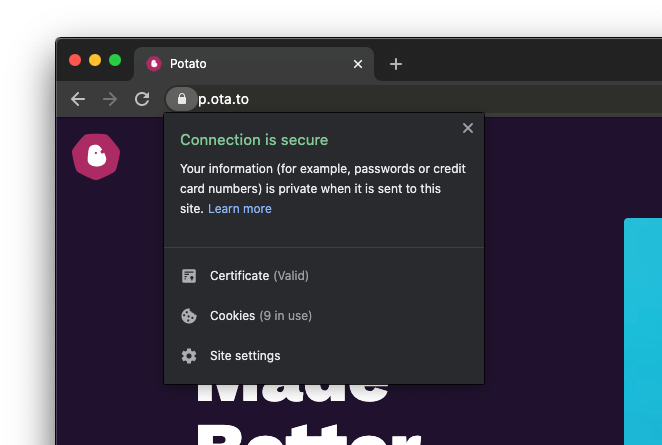
You can also click on the padlock icon to show relevant information.
TCP/IP
Transmission Control Protocol (TCP) is responsible for ensuring data requested through HTTP gets to you in one piece as quickly as possible. It does this in a few key ways:
- Firstly, it divides data into packets.
- It then transports these packets individually taking steps to mitigate risk of delay or delivery failure. Such risks include network congestion, unpredictable network behaviour and network traffic, that is, the amount of data moving across a network at a given point in time.
- Finally, it reassembles these packets ensuring all data is accounted for and in the correct order.
Internet Protocol (IP), amongst other things, provides an address system known as IP addresses. All internet connected devices have a unique IP address which takes the following format: 000.000.000.000. The most recent version of IP addresses, IPv6, exists for the purposes of relieving a projected shortage of IP addresses which have the following format: 0000:0000:0000:0000:0000:0000:0000:0000. You can find your IP address by searching for “What is my IP” in your browser. These addresses are used to ensure data is delivered to the correct host. Essentially TCP/IP is how and where data gets delivered.
DNS
A Domain Name Server can be thought of as a huge address book and is typically provided by domain name registrars. Typing a domain name into a web browser’s address bar triggers a request to a DNS server. The DNS server communicates with a hierarchical chain of independent, task specific DNS servers until the IP address of the requested domain is found. This IP address is then returned as a response to the client. The client can then request the resources it needs to load a web page from said IP address. DNS servers fall into one of four categories: Recursive resolvers, root nameservers, TLD nameservers and authoritative nameservers.
Let’s look at the DNS system in a step-by-step narrative. A resolver sits between the client and the remaining nameservers (root, TLD and authoritative), it receives requests in the form of domain names from the client.
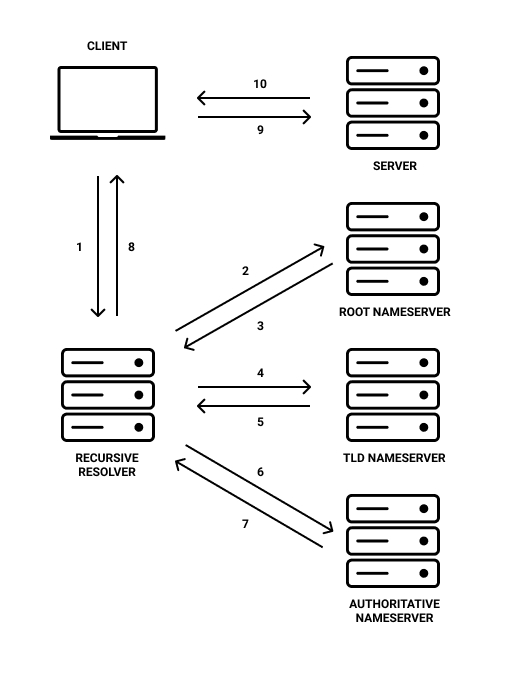
Having received a request, the resolver sends domain information onto the root nameserver in the form of a request of its own. A response from the root nameserver directs the resolver to the TLD nameserver. TLD nameservers contain information specific to a domain extension, be it .com, .co.uk, .org, etc.
The resolver, now knowing which TLD nameserver to communicate with sends a request to said server. A response directs the resolver to the authoritative nameserver. Sending a request to the authoritative nameserver is resolved in a response containing an IP address. At this point the resolver has communicated with each of the DNS server types and has obtained all the information it needs.
The resolver then caches the data to speed up future requests to the same domain and responds to the client with the obtained IP address. The client, having obtained the IP address, now knows where to request domain specific resources from in order to render a webpage.
Throughout this process there’s a consistent pattern of whittling down where to look in an effort to locate the resources the client needs to render a webpage. In brief this takes the form of going from domain name, to the domains extension type (.com, .net, .org) to specific IP.
URL
IP addresses aren’t particularly easy to recall from memory. This is where URLs come in. A URL is a human readable address for locating resources needed to render a site.
A URL is constructed of different parts, each serving a purpose. Let’s take a URL and break it down into its individual parts.
http://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocument
Protocol (http):
This sets the protocol in which data is transferred across the Web.
Host (www.example.com):
This is what is used alongside DNS lookup to find the IP address of the server that contains our resources.
Port Number (80): These are sometimes seen in URLs. By default, HTTP uses port 80 and HTTPS uses port 443, but a URL like http://www.example.com:8080/path/ specifies that the web browser should connect to the HTTP server running on port 8080 of the target machine.
Path (/path/to/myfile.html): This is the path to the required resource on the server.
Query String (?key1=value1&key2=value2): Query String parameters are a list of key/value pairs separated with the & symbol. Values are optional.
Fragment (#SomewhereInTheDocument ): A fragment links to part of the resource itself. On an HTML document, for example, the browser will scroll to the point where the fragment is defined.
Loading a web page
Now we know the processes involved in obtaining an IP address let's look at how a client goes about rendering a page. Our client, having received the appropriate IP address from a DNS lookup, can request resources from the server specific to the submitted domain name. The server's initial response contains the pages HTML. The parsing of this HTML by the browser includes sending additional HTTP requests for any resources the file references. Typically this will include Javascript and CSS but can also include images, fonts, audio and many other asset types.
Having acquired the assets it needs, the browser runs through a series of processes. Firstly the HTML is transformed into a Document Object Model (DOM). The CSS is then transformed into a CSS Object Model (CSSOM). These two models are then combined to form the Render Tree.
The browser then uses the information from the Render Tree to perform layout and painting of the elements which make up the page. The Layout operation is concerned with calculating the size and location of each element. The Paint operation is concerned with creating layers for the visible properties of each element such as border, background color, gradient, shadow etc. The final step in the process is the Compositing operation where the browser begins to render to the screen. It’s worth noting that these steps can occur after the initial page render as well. For example, the Paint step would be required during resize and animation events too.
This sequence is known as the Critical Rendering Path, something worth getting familiar with. It helps developers pinpoint performance bottlenecks and to reduce heavy rendering tasks that would affect a users experience.
For further reading on these processes I recommend this article on how the browser renders a web page. Google provides resources that cover performance, here’s their overview page titled critical rendering path. It covers a broader base and makes note of key things to avoid such as render-blocking CSS.
In Summary
We’ve covered a huge chunk of the processes and technologies involved in making the web work. From submitting a URL through to the page being rendered on your device. This article is intended to be a succinct overview of the ecosystem as a whole, as such, potentially overwhelming details have been deliberately omitted. Don’t let that stop you from taking what you now know and conducting your own further research. I hope you’ve found this useful, if anything you’re better prepared for making informed architecture decisions and understanding where bottlenecks or errors may be happening. At the very least you’re now equipped to effectively answer the common “What happens when you submit a URL?” interview question!